
JVM主要由以下部分造成:
- segment memory
- filter query cache
- shard request cache
- field data cache
- indexing buffer
- 超大搜索聚合结果集的fetch
- 对高cardinality字段做terms aggregation
1. segment memory
es底层是用Lucene实现,一个shard由多个segment组成,segment是Lucene的最小单位。当一条数据写入es时,底层是写入Lucene,此时数据仍然在Lucene内存之中,无法被搜索。
为了能够搜索数据,es会执行refresh操作,该操作时间间隔由索引级别的refresh_interval参数控制,默认是1s。执行了一次refresh后,数据在第一时间内并不会写入磁盘,而是写入文件系统的buffer(这时就是segment了,只不过在内存中),此时如果宕机了,那么buffer也丢失了,所以,es推出了日志系统:translog,用于确保这个buffer能最大程度写到磁盘中。如下图所示:1
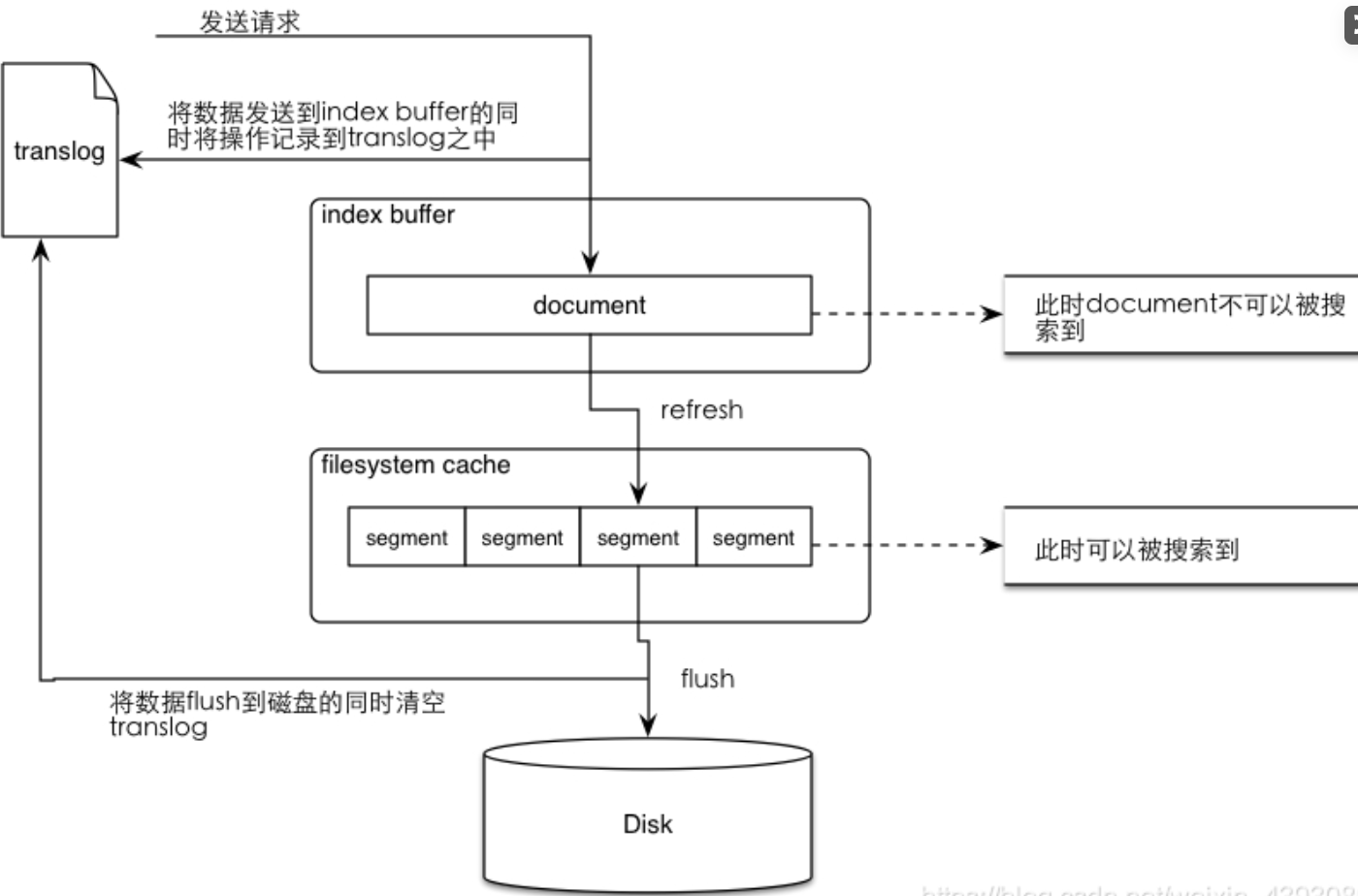
当达到index.translog.flush_threshold_size时(默认512mb),es会触发一次flush操作,将buffer写入磁盘,此时数据就完成了持久化。
随后,es会周期性检测segment,将一些小的segment合成一个大的。
既然segment是一个文件,那么怎么会占用JVM呢?
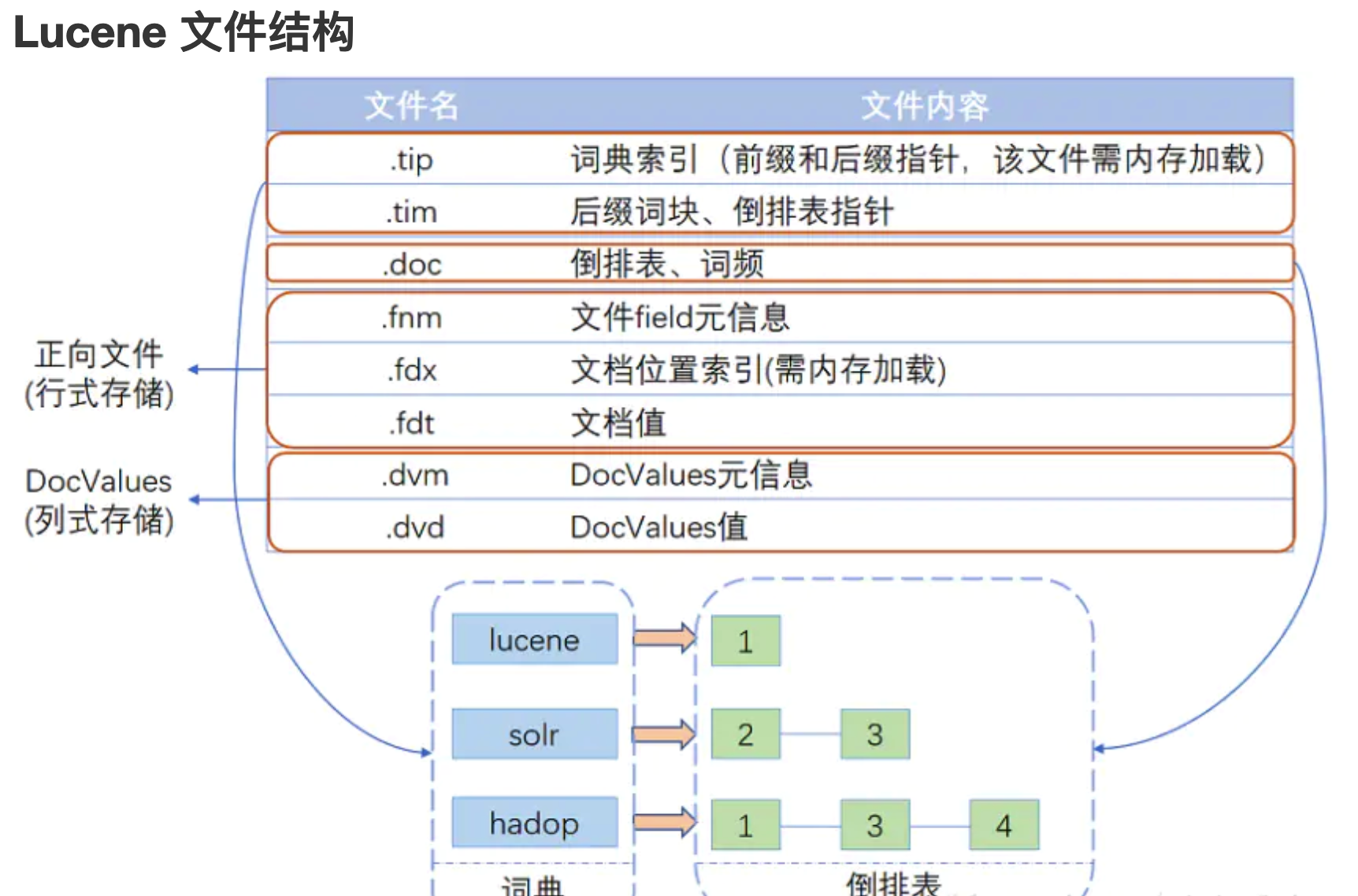
索然segment是一个文件,但如果一个一个搜索segment来寻找数据,那么es根本无法做到如此快速的搜索。所以segments会生成倒排索引,倒排索引就相当于是查字典的目录,通过一个单词(Term)所在页码,可以迅速找到单词的意思。
同样的,es会生成一个词典(Term Dictionary),指出那个单词在哪个文档。但,如果词过大,也无法放入JVM,所以es采用了前缀树(Term Index),这样就知道了A开头的单词在词典的哪一页,然后跳到这一页,那么搜索起来就很快了。原理大概如此,但es实现的更加细节,从4.0版本开始采用了FST数据结构,更加有效的减少了JVM占用。
FST对应.tip文件,Term Dictionary对应.tim。
但即使是用了二层索引FST,在数据量级到达10TB时,仍然会占用约10GB的JVM。所以,将FST放入JVM堆内存,限制了ES对大数量级数据支撑。因此,在ES7.3版本,将FST放入堆外内存,由MMAP映射读取,大大降低了JVM堆内存使用,据统计可以降低70%多。2而且,在ES7.7版本,将_id的FST也移动到了堆外内存。
所以,JVM中有一部分内存是segment memory占用的,并且无法被GC回收。通过API,可以查看每个node的segment memory占用:
11GET _cat/nodes?v&h=name,port,sm
如果segment memory过大,可以通过以下方式,减少占用:
- 删除或关闭不用的索引
- 手动定期做segment合并
2. filter query cache
filter query cache也叫做Node query cache,因为其查询结果保存在node上,会被每个分片共享,特点是:由ES静态配置(indices.queries.cache.size: 10%),无法被GC回收,采用LRU策略进行覆盖,可以关闭3。
根据ES官方文档显示4,一个DSL会被分为Query context和Filter Context,Query context计算文档匹配分数(relevance score:_score),表示该文档与查询字句的匹配程序;Filter context不会去计算分数,是一个二极管,表明文档是否匹配。如:filter子句、must_not子句、constant_score子句和filter aggs。
3. shard request cache
shard request cache是分片级别的缓存,每个分片都保存各自的搜索结果。默认只缓存size=0的请求,比如hits.total、aggregations、suggestions5。
由ES静态配置indices.requests.cache.size: 1%,默认启用,可以动态关闭,通过以下API可以观察各节点使用情况6:
11GET /_nodes/stats/indices/request_cache?human
4. field data cache
filed data也叫做正排索引,如果说倒排索引用于快速的找到文档,那么正排索引就是为了对一个字段做排序或统计。试想一下,统计某个字段的可能性,需要将所有文档读取一遍,此时如果没有缓存,那么对磁盘IO来说是一个巨大的负担。
某个字段正排索引结构如下,是倒排索引的转置。在ES2.0之前,是由fileddata实现,默认对每个字段(除了analyzed字段)启用,存在于JVM堆内存。
51Doc Terms2-----------------------------------------------------------------3Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the4Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer5Doc_3 | dog, dogs, fox, jumped, over, quick, the
对于text类型默认是没开启fielddata,因为分词结果太多,会严重占用JVM堆内存(开启之后,也只会在第一次聚合时才会加载到内存)。ES2.0之后,开始逐渐由doc_values实现(默认启用),存储在磁盘上,通过mmap访问,不支持text字段7,如果ES版本高于2.0,并且field data cache占比很高,那么你得考虑一下是不是对analyzed字段做了排序或者聚合。
当进行聚合或排序时,ES会将聚合或者排序后所需的正排索引放入JVM堆内存,这被称之为field data cache,只有当达到限制或者segment合并时才会被清理。默认是无上限的,可以静态修改:
11indices.fielddata.cache.size: 20%
但indices.fielddata.cache.size必须小于断路器的大小,断路器默认40%8:
41POST _cluster/settings2{3"indices.breaker.fielddata.limit" : "40%"4}
当filed data cache过大时,还可以手动清理:
121POST /_cache/clear2
3POST /my-index-000001,my-index-000002/_cache/clear4
5POST /my-index-000001/_cache/clear?fields=foo,bar 6
7//Clears only the fields cache8//Clears only the query cache9//Clears only the request cache10POST /my-index-000001/_cache/clear?fielddata=true 11POST /my-index-000001/_cache/clear?query=true 12POST /my-index-000001/_cache/clear?request=true5. Indexing Buffer
用于缓存写入的document,默认占用JVM堆内存的10%,节点上的所有的分片共享,可以被GC回收。可以通过静态设置:
11indices.memory.index_buffer_size:10%
6. 超大搜索聚合结果集的fetch
聚合或者取数据时,一次性要求返回过大的数据,会导致JVM堆内存使用率快速上升,比如:from+size深度分页搜索。9
7. 对高基数字段做桶聚合
高基数字段是指一个字段的存在的可能性比较多,比如IP字段,可能存在几十亿种可能性,使用terms聚合时,就会导致内存中的桶过多。9
Reference
Comments NOTHING